When designing distributed systems it’s important to know CAP(Consistency, Availability and Partition Tolerance) theorem in order to understand trade offs in designing different distributed systems.
CAP Theorem states that in a distributed system, one can choose two out of three - Consistency, Availability and Partition Tolerance.
What does these three terms mean:
- Consistency - means a client sees the same data irrespective of the node it connects to. If a node doesn’t have the same data(most up to date) due to a network partition then it’s not available to receive requests.
- Availability - means a client receives a response even if some nodes are down in a network. This means nodes which are network partitioned will return inconsistent data.
- Partition Tolerance - means the distributed system is unaffected by a network partition. This is only possible for classical systems where only one node serves the request.
According to CAP theorem there can be CA, CP or AP systems. Lets look at these individually.
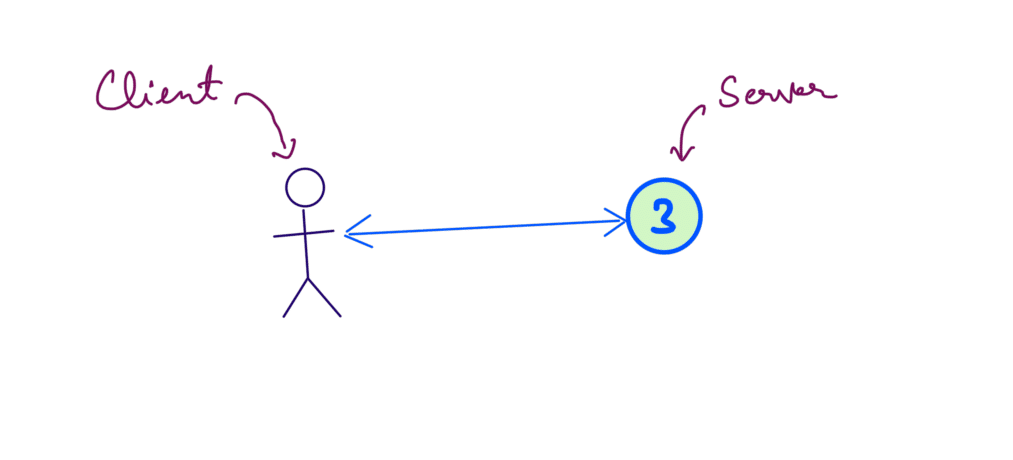
Classical CA system
All products starts as a CA system, we have one server and one client.
Things are simple.
Our client writes and reads data from the single server. There is no possibility of a network partition as there is only one server. These type of systems are called CA system.
Network Partition in Distributed Systems
As the product grows there comes a need to scale our system. Lets assume for this scenario we need to serve clients in Asia and Europe as well. In order to achieve this we deployed cross region servers in Europe and Asia.
Assume that our servers some data. Asia clients read and write to Asia servers and Europe clients read and write to Europe servers. This is an example of a distributed system.
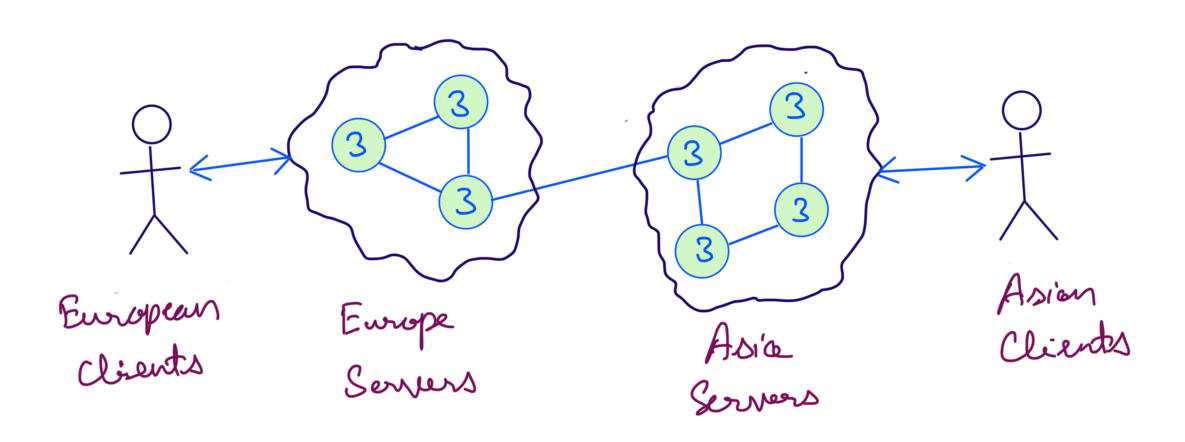
We’ve scaled our system to serve Asian and Europe clients, however one fine day a internal network failure occurred due to which Asia servers cannot communicate with Europe servers and vice versa. This is known as a Network Partition.
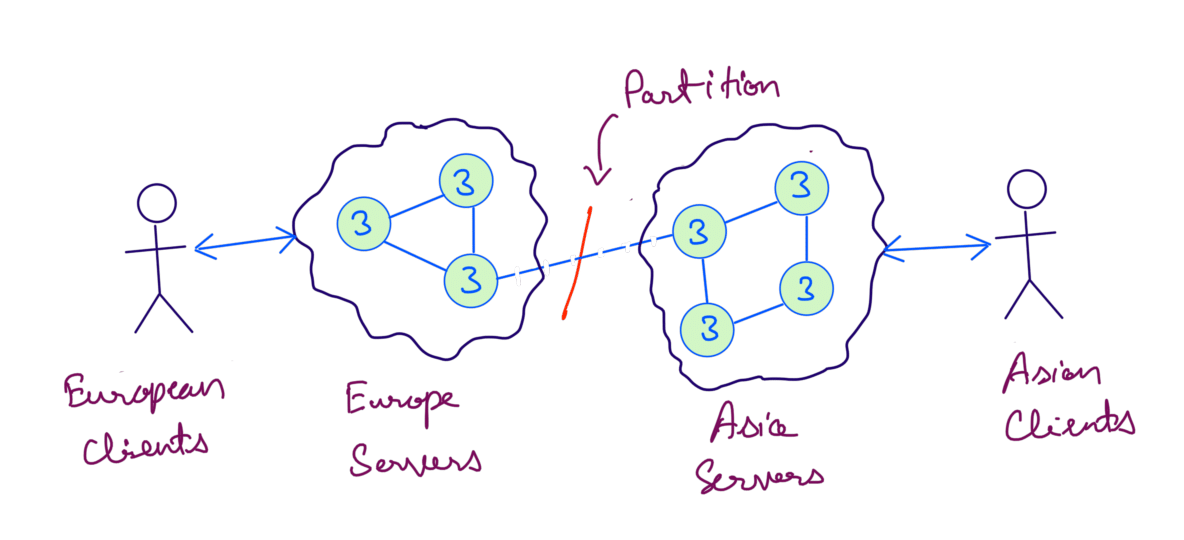
What’s a Network Partition ?
In a distributed system a Partition(or a Network Partition) is when a set of servers are not able to communicate with another set of servers.
Due to a Network Partition updates on Asia servers cannot be synced to Europe servers and neither can Europe servers sync updates back to Asia servers.
Woah, what do we do ?
Let’s think logically - one way is to stop taking requests for Europe servers.
This means Europe servers will not available. Once network heals the data can be synced to Europe servers.
Well what about Europe :(
Ok, how about we allow updates to Europe servers.
Since there is a Network Partition the data will not be synced between them, this will cause inconsistency. Once the network heals we can resolve conflicts and make the two server sets consistent.
In real world, one cannot avoid a Network Partition.
As we saw then it’s the matter of choosing between - Consistency or Availability. Doing so we either get a CP or an AP system.
Next we’ll discuss real scenario where we understand how to choose between Availability and Consistency.
AP system - Boxing match
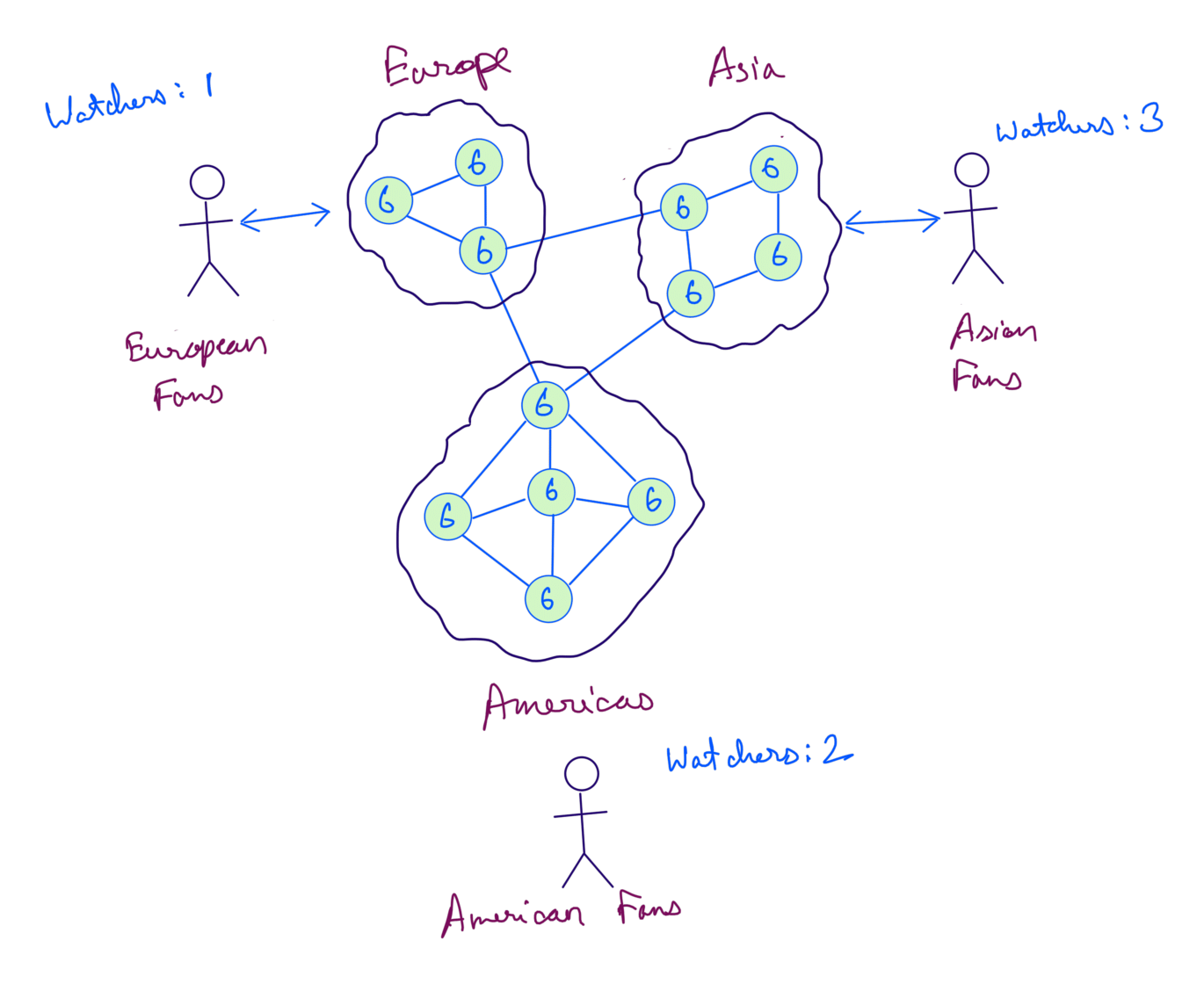
Scenario 1 - We’ve build a live streaming platform for boxing matches. Now we need to show the watch count of the match. To make it scalable we’ve deployed servers across Americas, Asia and Europe. We’ll store the total watch count in these servers.
As the watchers changes in a specific region the count is also updated for that region. The servers in that region then syncs it to others servers across region.
In the below diagram we’ve 3 people watching from Asia, 2 from Americas and 1 from Europe. The total watch count then becomes 6 which is synced to all the servers:
However, during a live match the Asia servers gets partitioned from the rest of the system:
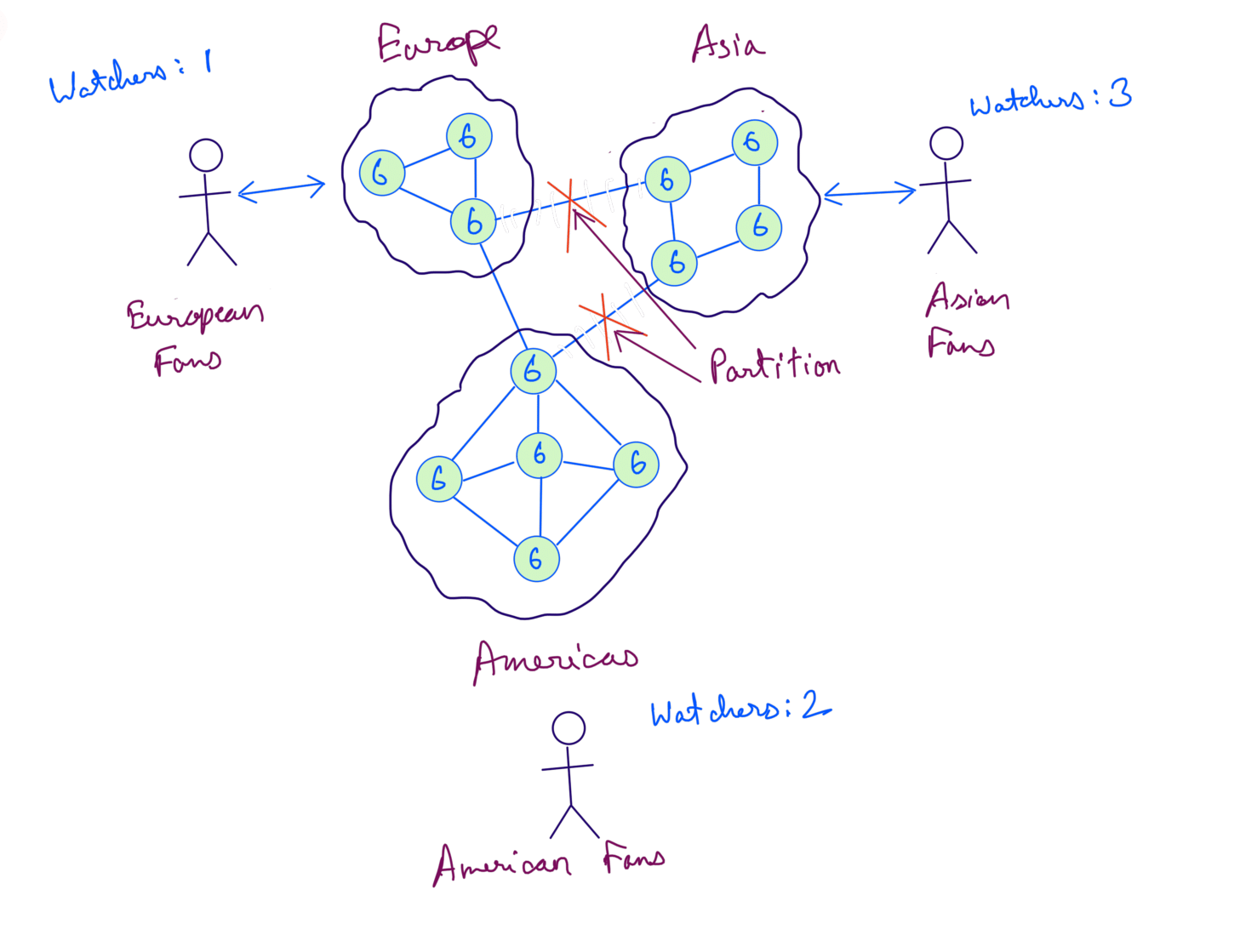
Now updates to Asia servers cannot be synced to Americas and Europe servers. If the watchers increase in Asia, the total watch count in Americas and Europe will still remain the same.
How do we resolve this ?
Lets look at the business use case, it doesn’t matter if the total watch count is the most up to date as long as it becomes eventually consistent. We can safely assume:
The watch count can be inconsistent for a period of time. This means we can choose Availability over Consistency.
We’ll allow watchers to be updated for Asia servers and the rest of the servers. This will cause the total watchers to be inconsistent as shown below:
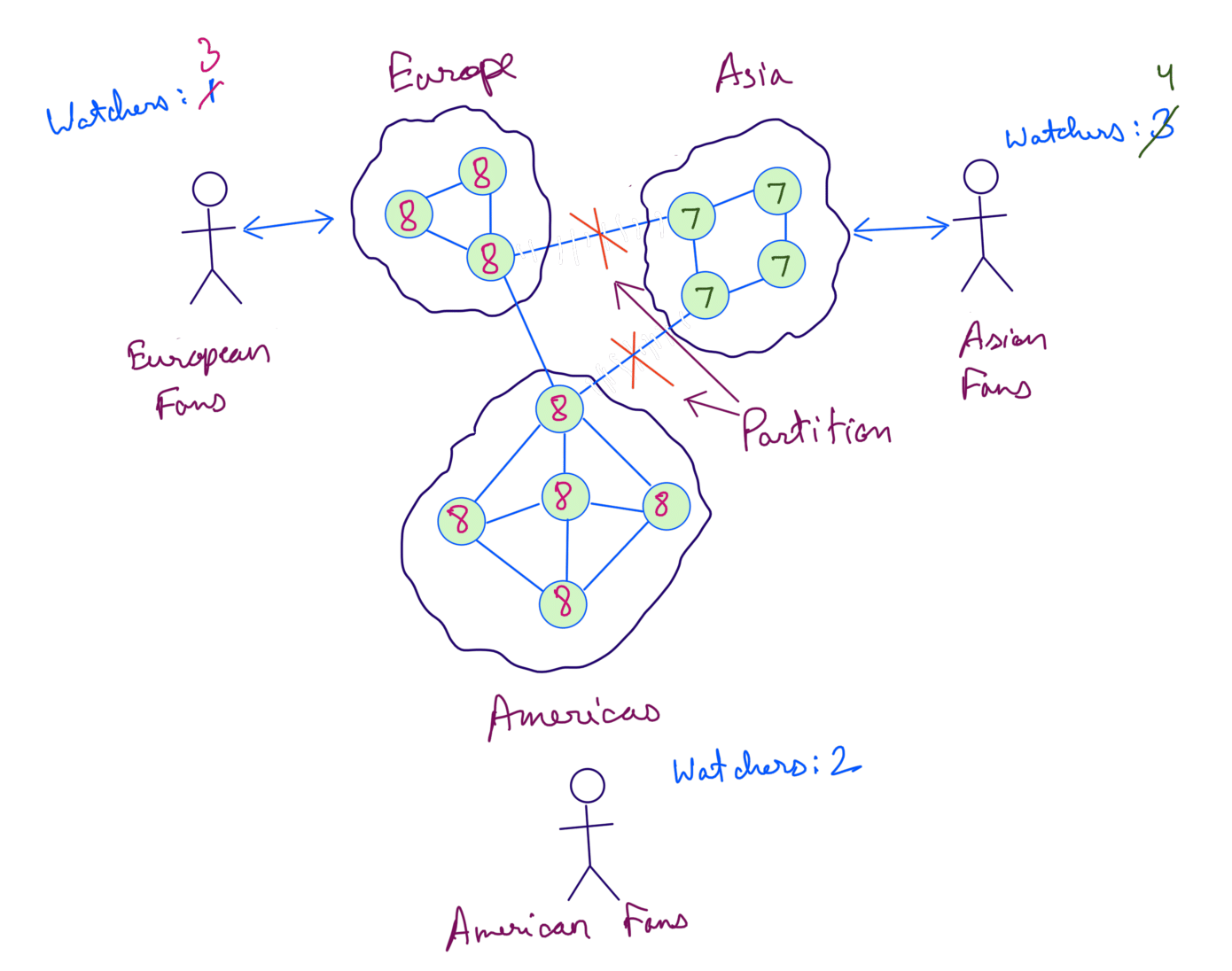
When the network heals, Asia servers and rest of the servers can sync their data with each other and make the data consistent. This is known as Eventual Consistency.
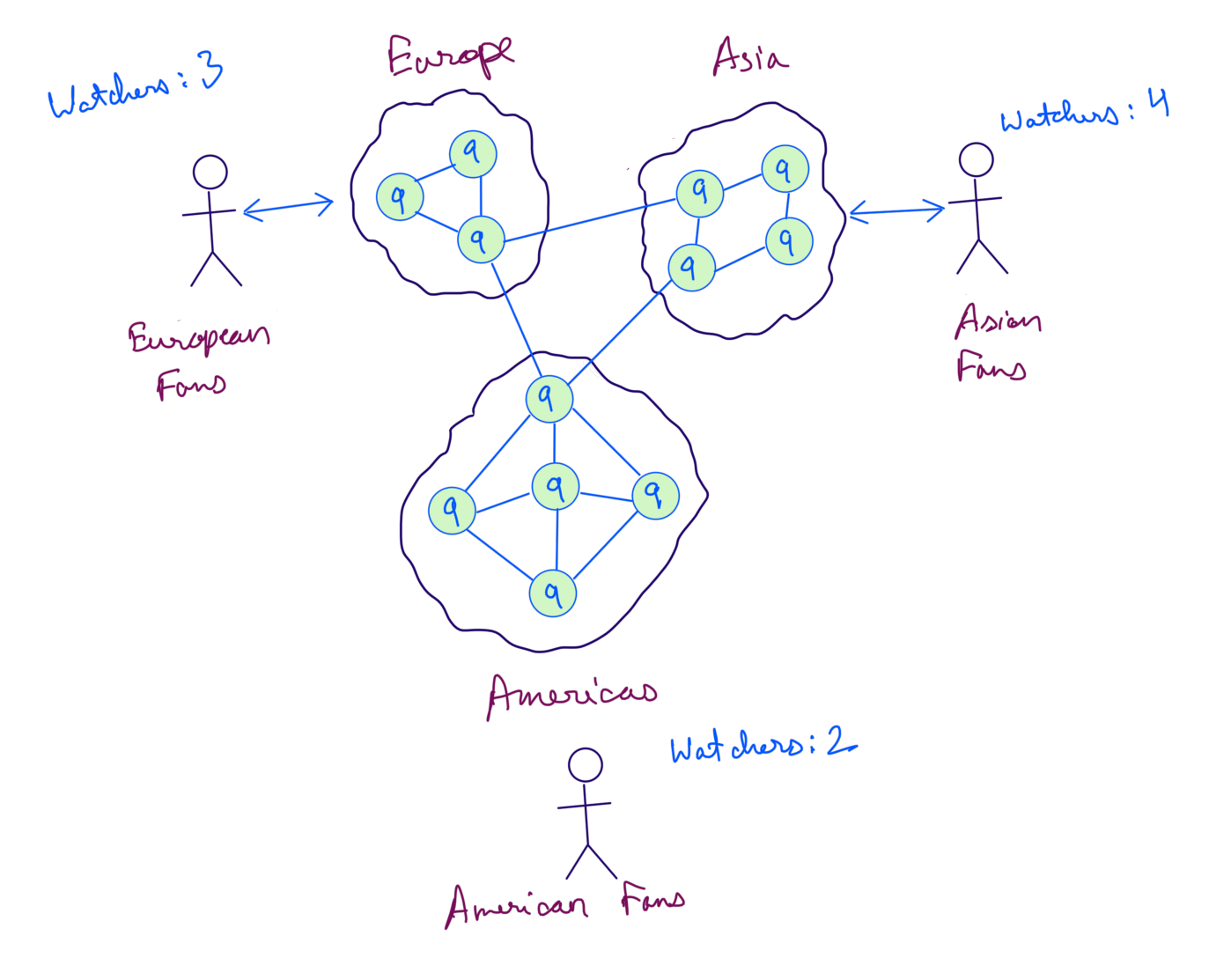
As we chose Availability over Consistency, this is an example of an AP system.
How do we make the data consistent ?
One issue is how does the servers know what changed in different regions.
A simple way to achieve this is to create a vector. The idea is save the count per region separately. To do so we create a 1-D array or a vector and store the watch counts of different regions in different indices.
For our case, the vector will be [4,2,3]. Index 0 holds the Asia watch count, index 1 holds the Americas watch count and index 2 holds the Europe watch count. This vector is synced to different servers.
CP system - Bidding system
Scenario 2 - We’ve build a bidding system for auctioning valuable items. We now have to scale it globally. To make that possible we’ve deployed servers across Americas, Asia and Europe. The Asian bidders update the Asia servers and similarly Americas and Europe bidders update servers in their region. This how our system looks like:
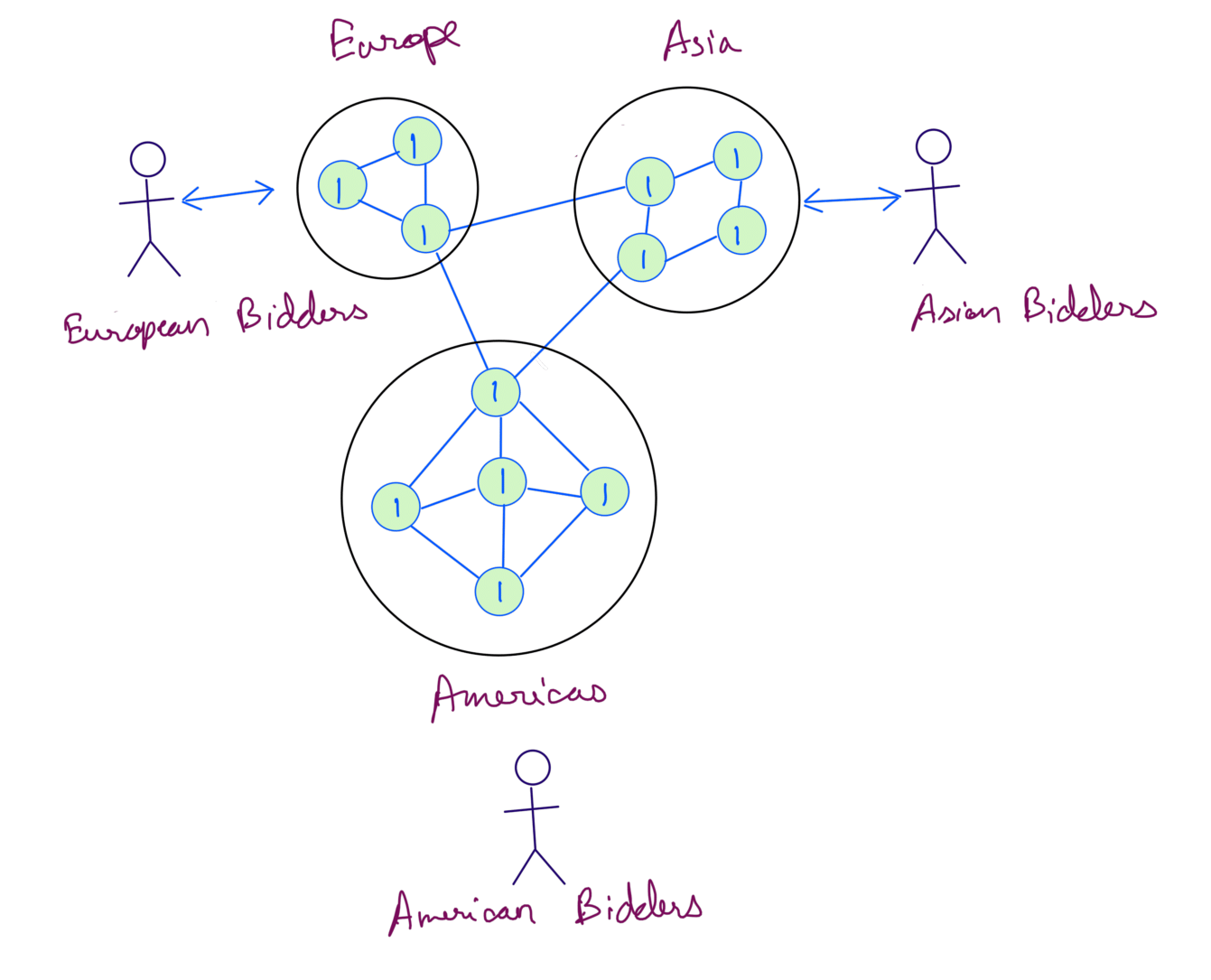
Lets say the initial bid for the item is 1 million. Bidders from each continent can bid a higher value than the current bid. It’s important to note here that all the bidders must see the most up to date bid.
Since internal network failure are possible in real world, we need to make sure our system is tolerant to it. To do so we imagine what will happen in case Asia servers are Network Partitioned due to a internal network failure.
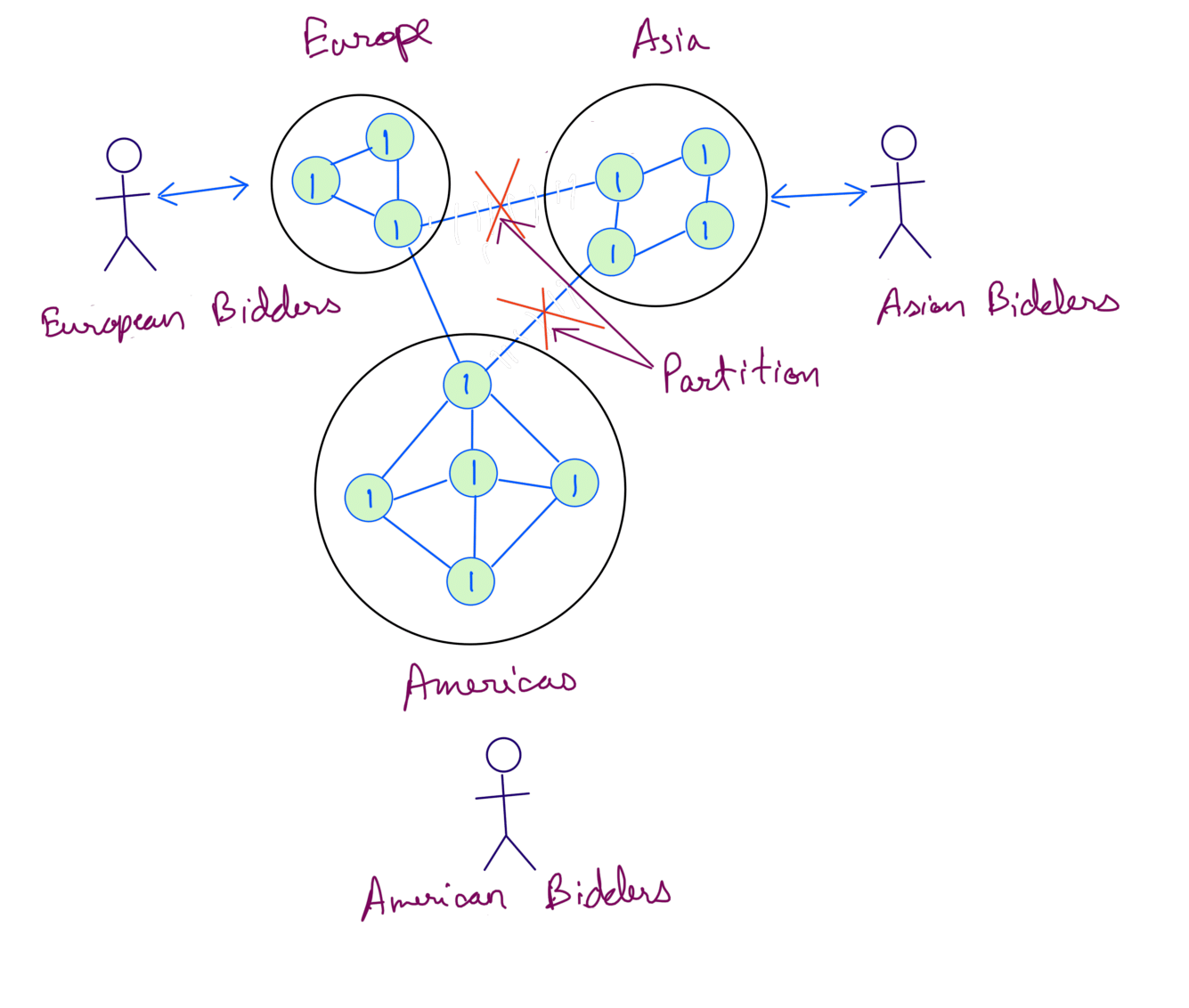
Now any bids done by Asia bidders cannot to synced to servers in other regions and any bids done in Americas and Europe cannot be synced to Asia. Because of this bidders will not see the most up to date bids.
How to resolve this ? Should we go for Availability or Consistency ?
Let’s say we choose Asia servers and rest of the servers to accept bids.
Now somebody in Asia bids 3 Million, this gets updated in Asia servers. Europe and Americas bidder still see 1 Million. Now a European bidder bids 2 Million.
The system allows this update, but in actuality the Asia bidder had already bid a higher value than 2 Million so this should not have been allowed.
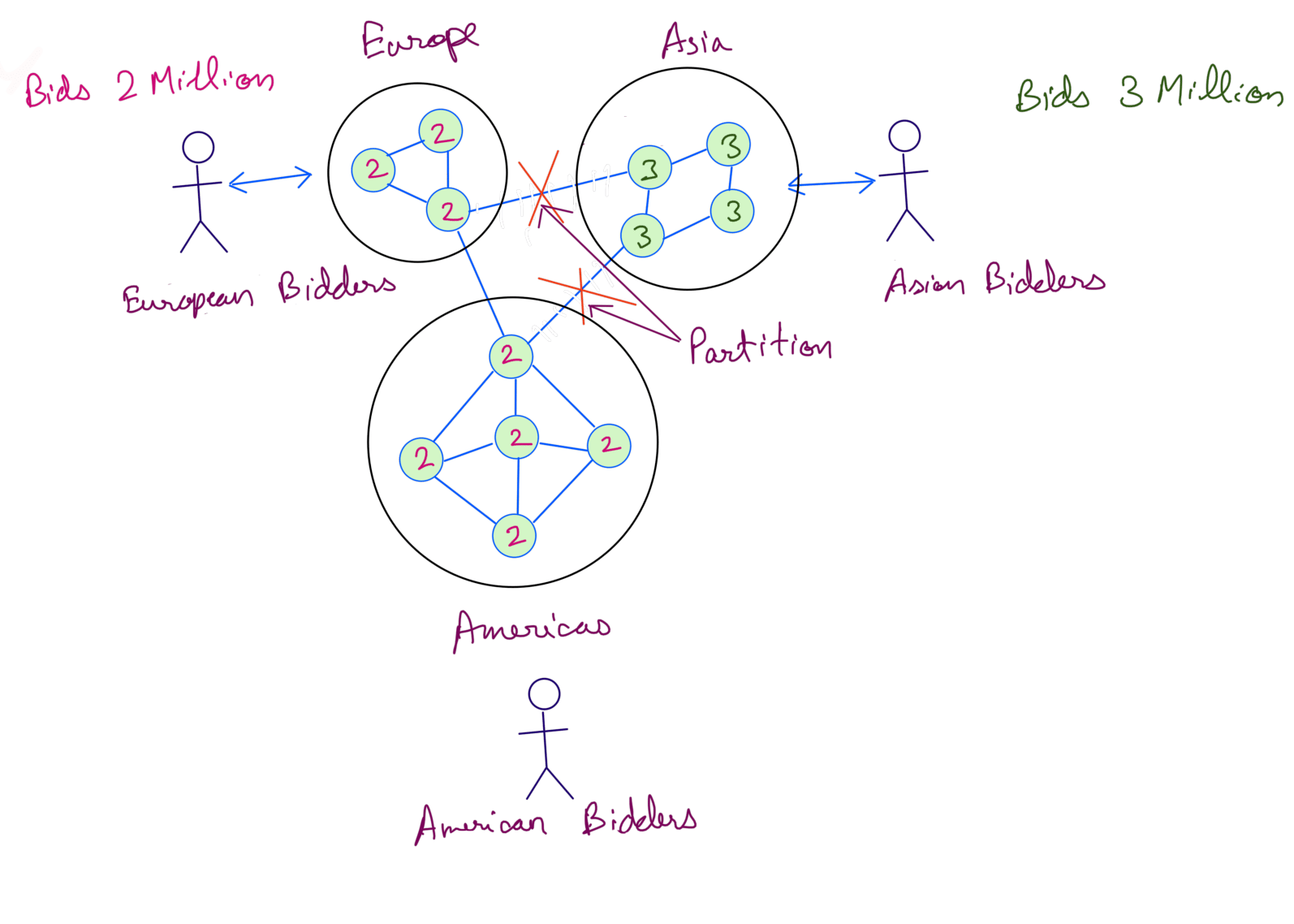
The issue is there are two biddings now for the same item, Asia bidders see 3 Million while European and Americas bidders see 2 Million. While all the bidders must see a consistent bid.
To make sure bidders see a the most up to date bid we must choose Consistency over Availability.
Since bidding needs to be fair for all the bidders, we need to stop requests for all the servers until the network partition heals itself.
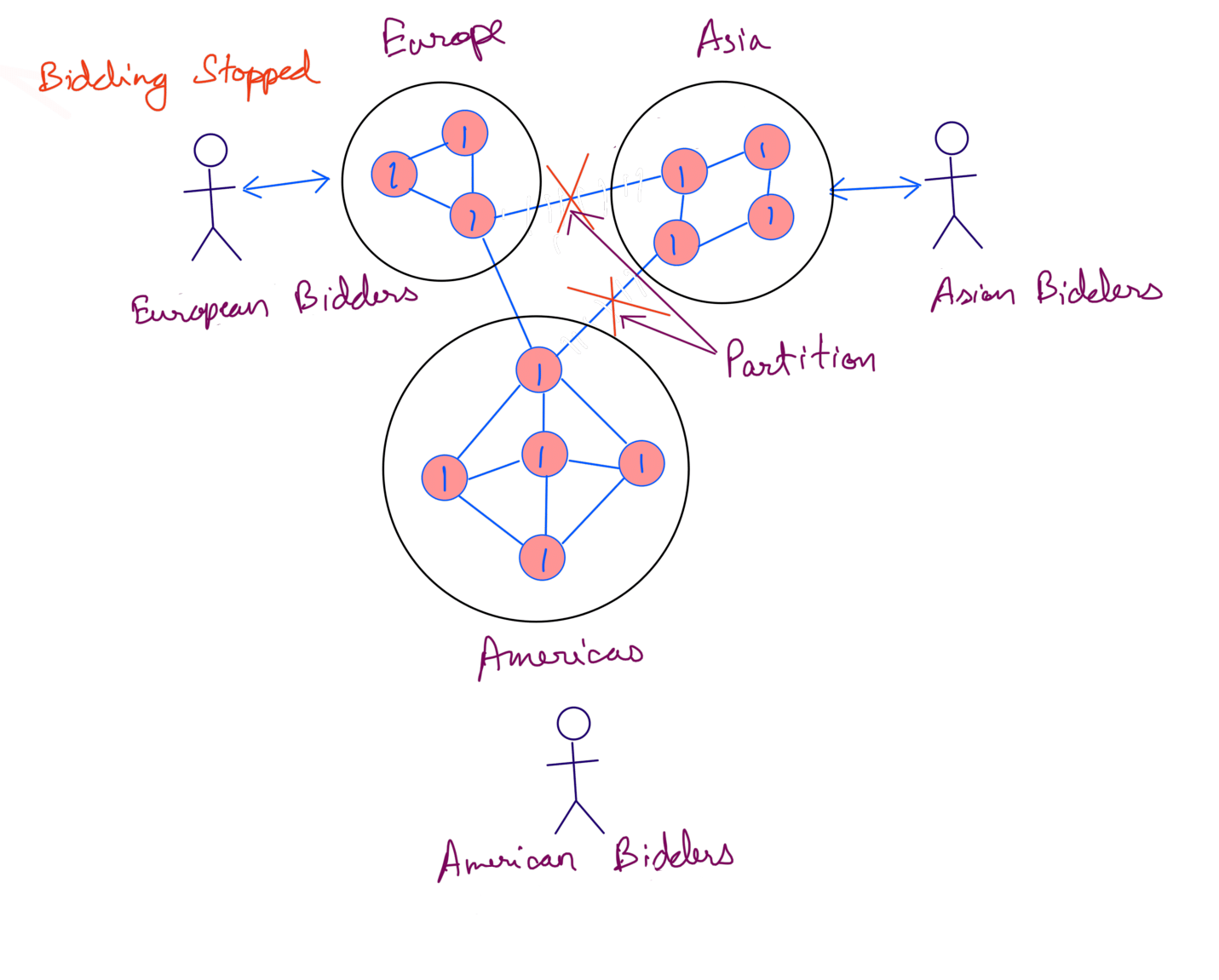
Once the network partition recovers we start the bidding again.
This time the Asian bidder bids 3 Million, the European bidder sees the new bid and doesn’t bid 2 Million. It works because we chose Consistency over Availability making this an example of a CP system.
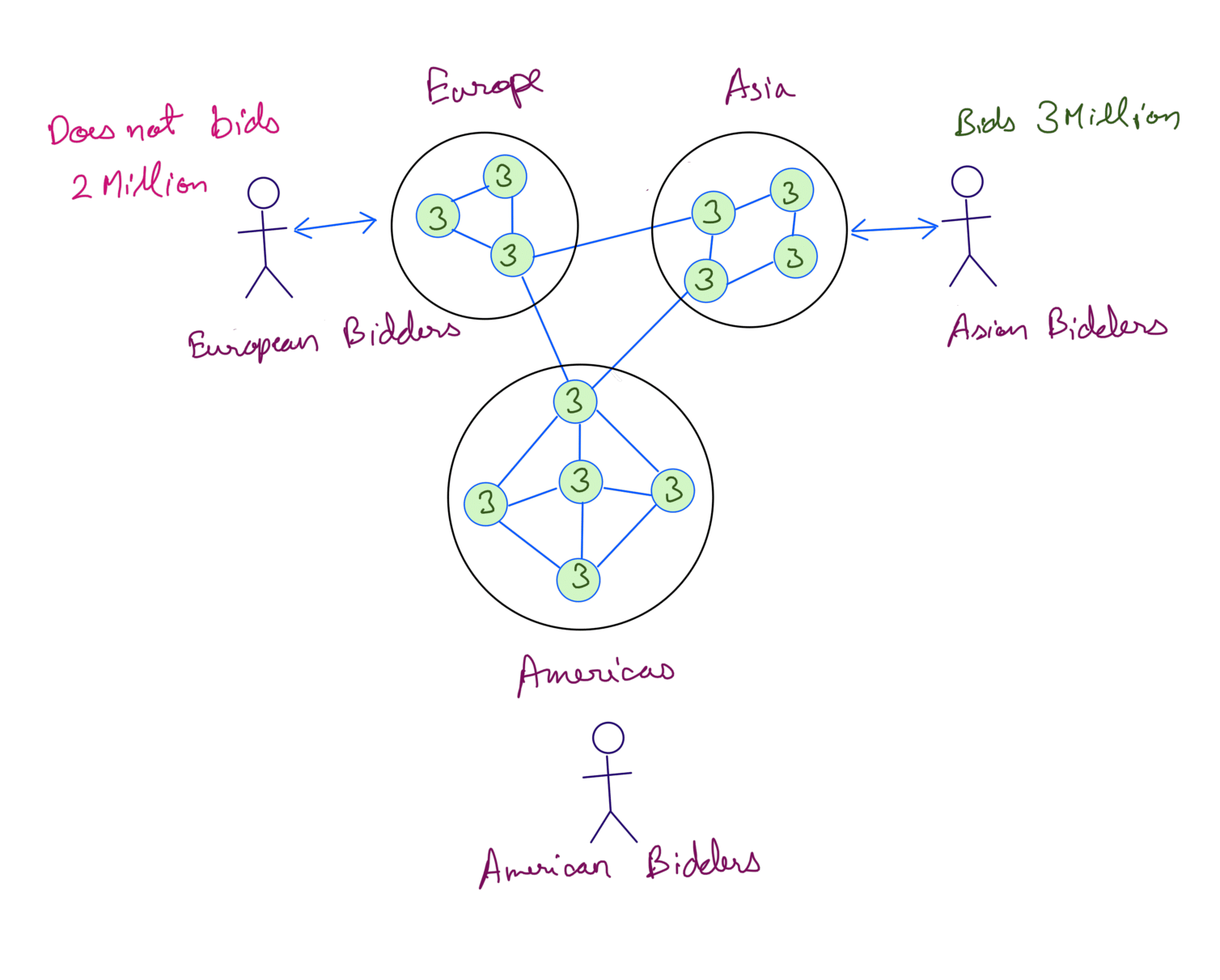
One last thing is how do we resolve concurrent updates ?
As we’re updating the same item, it’s possible for concurrent bids to happen due to latency in sync or bidding happening at almost the same time.
We can resolve such issues by using timestamp or epoch time to discard the bid which was done at a later time.
Building a low latency internal network will also reduce the chances of such scenarios happening.
and that’s all folks.