In this blog we’ll learn the basics required to scale an application. Lets start with how does the architecture of a small application looks like.
Basic API Architecture
At the most basic level any application has following parts:
- Client - which requests the API and gets back a response.
- Server - which processes the request and sends back the response.
- Database - which stores any data that the server needs to process any subsequent requests.
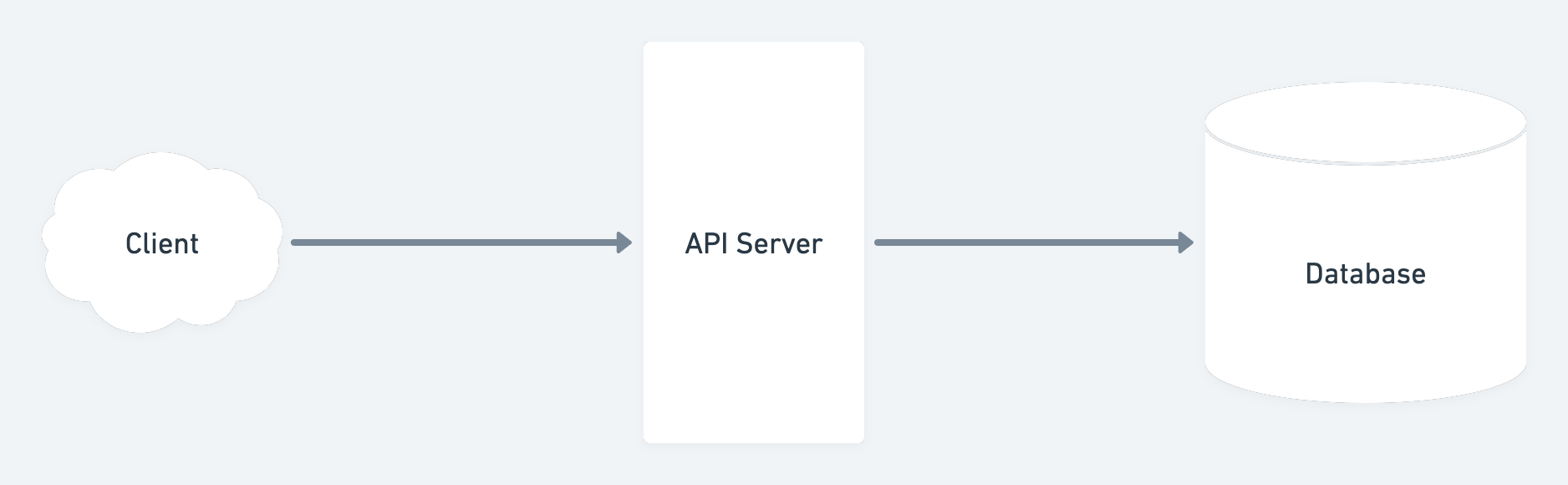
Let’s say we’re building view count feature for a Youtube like app. Whenever somebody views a video it increments the view count.
In the above diagram the client will send the video id being watched and the server increments the count and saves it to the database. To make our app scalable we’ll need to estimate the requests
Estimating requests
For estimating we’ll assume our server can process 10 requests per second and our relational database can handle 100 read/write requests per second:
- API Server - 10 req/s
- Database - 100 req/s
Now let’s say suddenly there is a spike in traffic increasing the requests to 100 req/s.
What should we do to allow our system to handle such change ?
One idea is to add more api servers and distribute the requests among them:
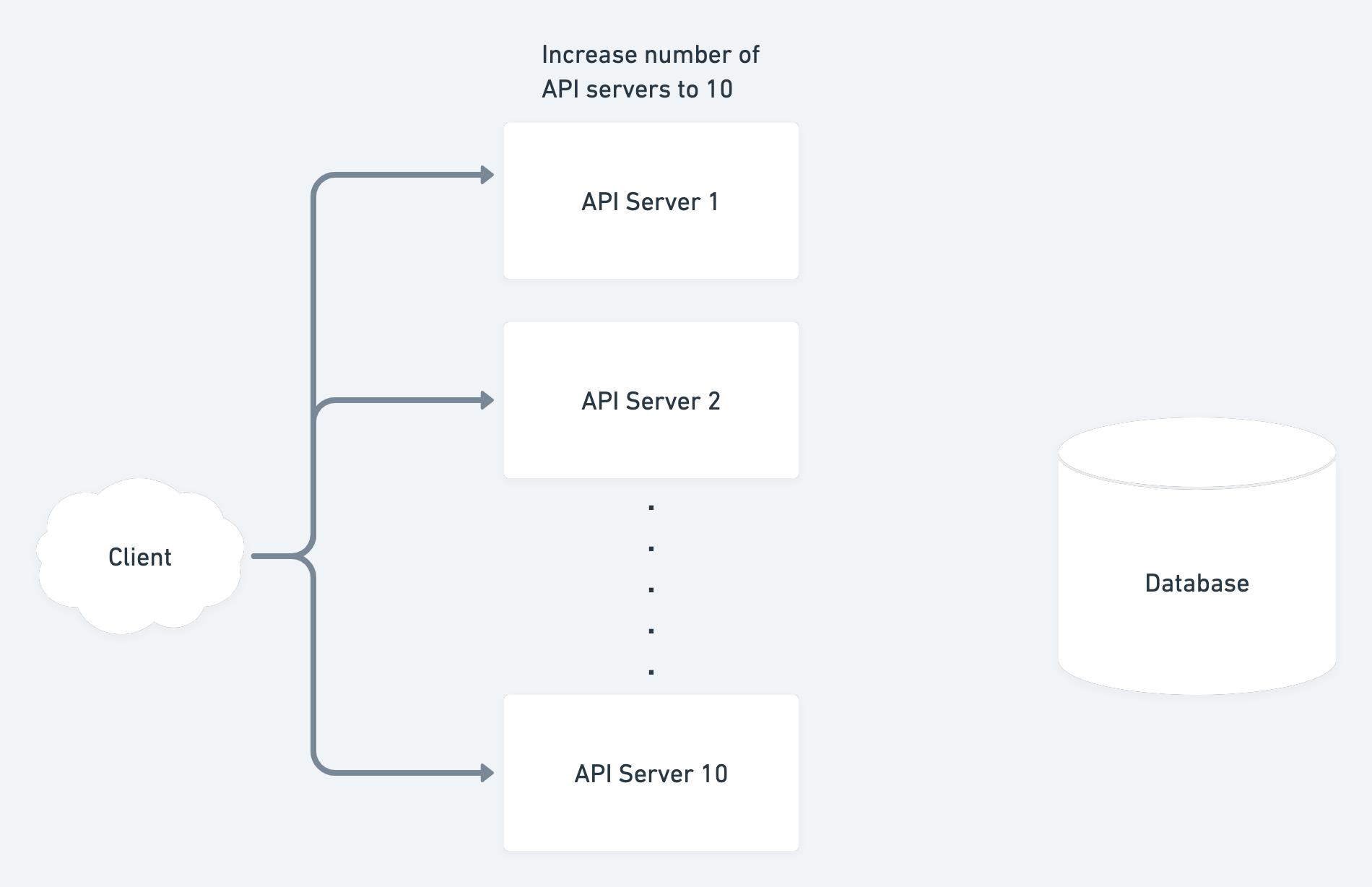
Let’s do some calculations to understand how much req/s can our system handle now:
We’ve added 9 api servers to our system.
Each server can process 10 req/s, if we distribute the requests evenly then
new req/s = (1+9) * 10 req/s = 100 req/s
Great now our system can handle spikes of 100 req/s.
Load Balancer
Another question to ask ourselves is who is going to distribute the requests to the different api servers ?
Here is where Load Balancer comes into the picture.
Load Balancer is a server dedicated for evenly distributing the requests to the API servers.
With a Load Balancer to our system looks like:
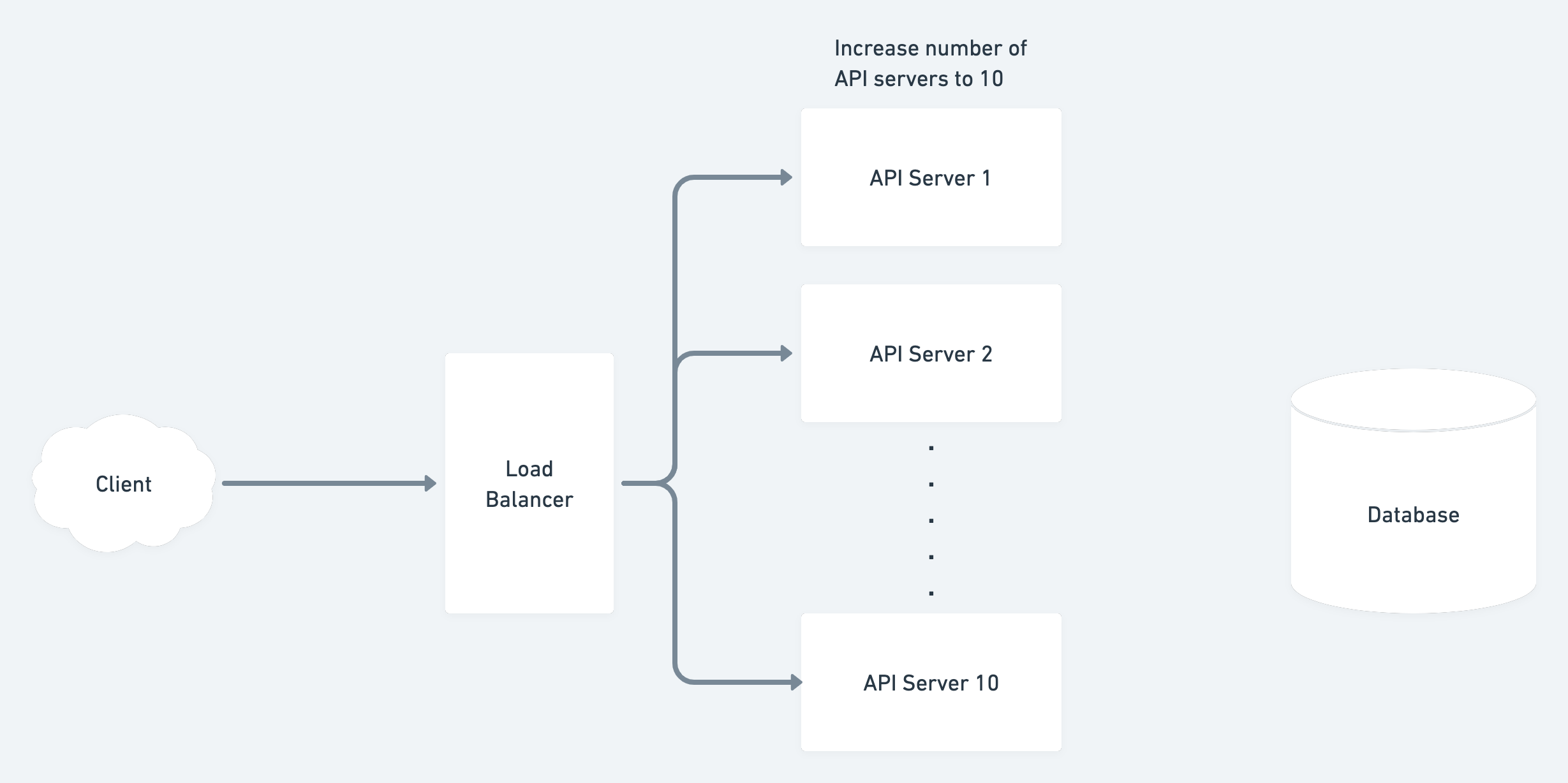
Ok so we now have multiple API servers and a way to distribute the load among them.
Stateless Service
We need to think about if adding a new server will incur some additional steps ?
Our API servers in our design are stateless.
Stateless service means that our API servers only processes requests and doesn’t persist any data.
When adding a new server we register it with the load balancer. Since they don’t have any state, the new server can start processing requests as soon as it is added.
Recapping:
Our system now has 10 servers and 1 database which can handle 100 req/s. Load Balancer ensures evenly distributes the requests to our servers.
Let’s take up a notch. How about we want to handle say 200 req/s ?
The first thought will be to add 10 more API servers. That’ll help in increasing the load API servers can handle to 200 req/s.
However, the bottleneck here is the database.
Our database can only process 100 read-writes/s, so we’ll have do something about our database as well.
Vertical Scaling
How to scale our relational database ?
One way to scale our database is by upgrading its hardware. Adding more memory and storage will allow our database to handle more requests. This is called vertical scaling.
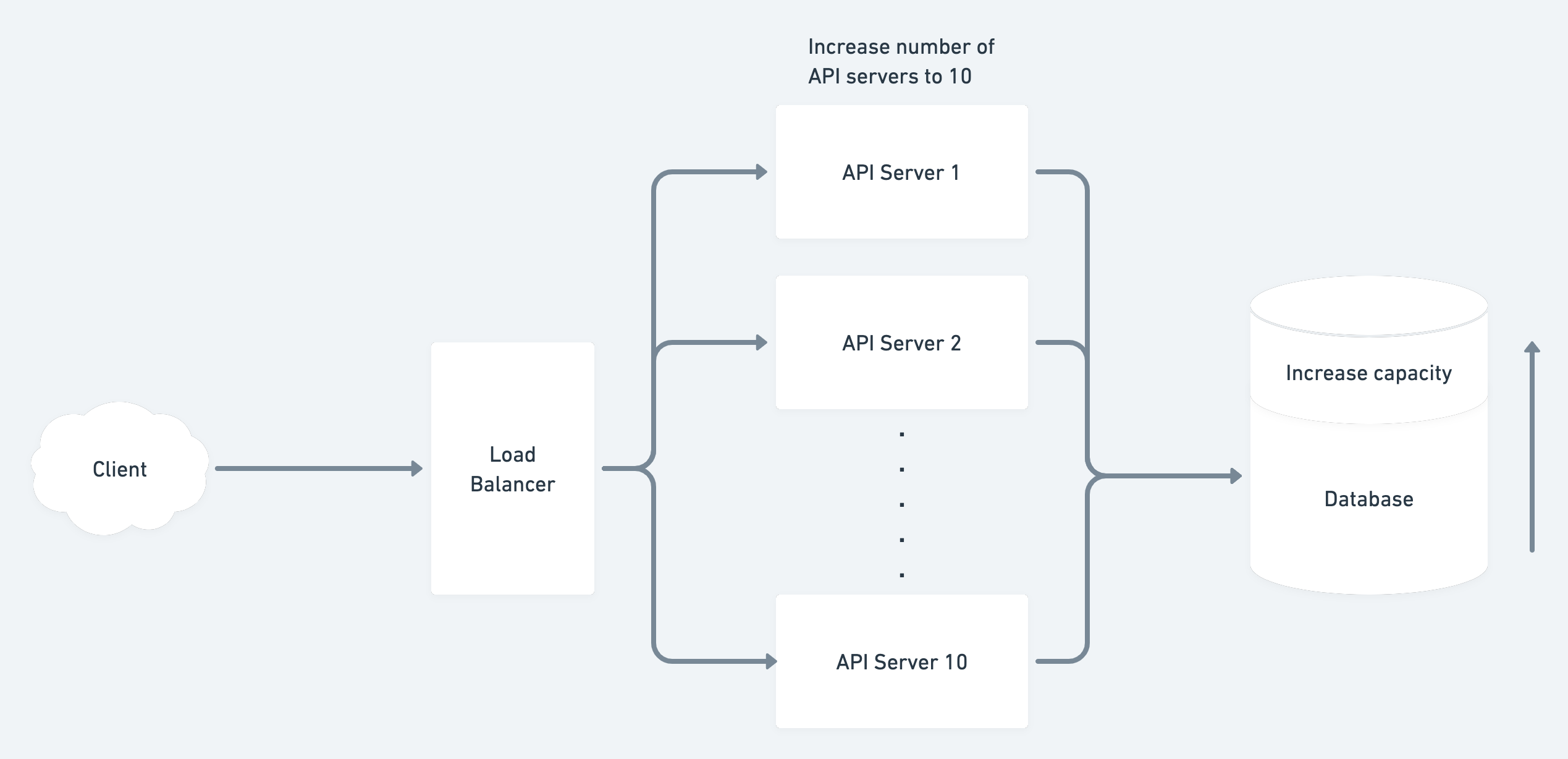
Although this is not an ideal solution since there are limitations to adding more memory/storage. Moreover it becomes costly as we add more and more memory/storage.
We can do similar to what we did for API servers, add more servers.
However keep in mind that database is a stateful service.
Stateful Service
Databases persists data which makes them a stateful service.
If we want to add another database server we’ll need to copy the current state into it. This is known as Replication:
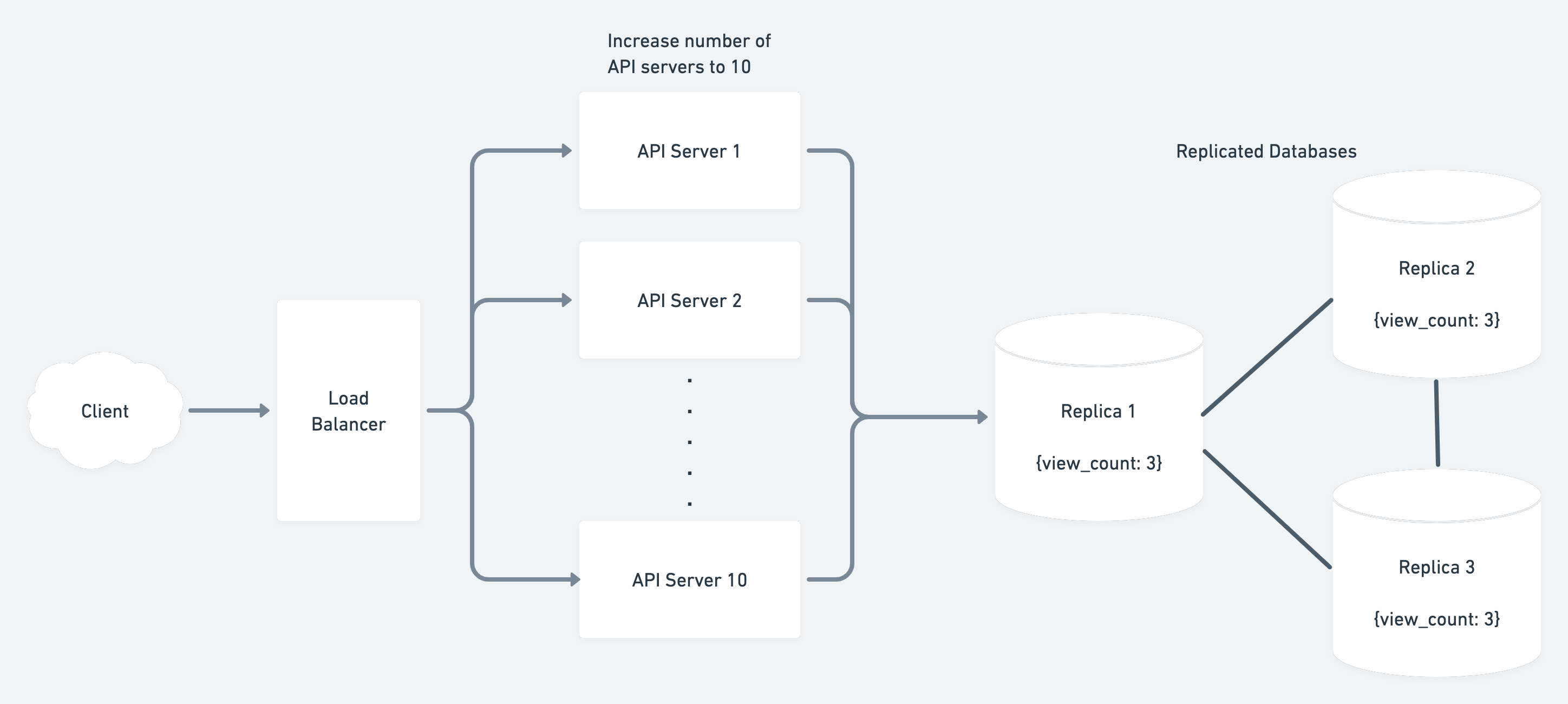
One thing to ask here is that what should we do about reads and writes for the replicas.
Should we allow writes to all servers ?
If so how do we handle conflicts then ?
Master Slave replication
To make sure write conflicts doesn’t happen we can adopt Master-Slave replication.
In Master-Slave replication one node processes all the write requests, known as the master node, and syncs the updates to the other replicas called the slave nodes. Read requests are processed by the slave nodes.
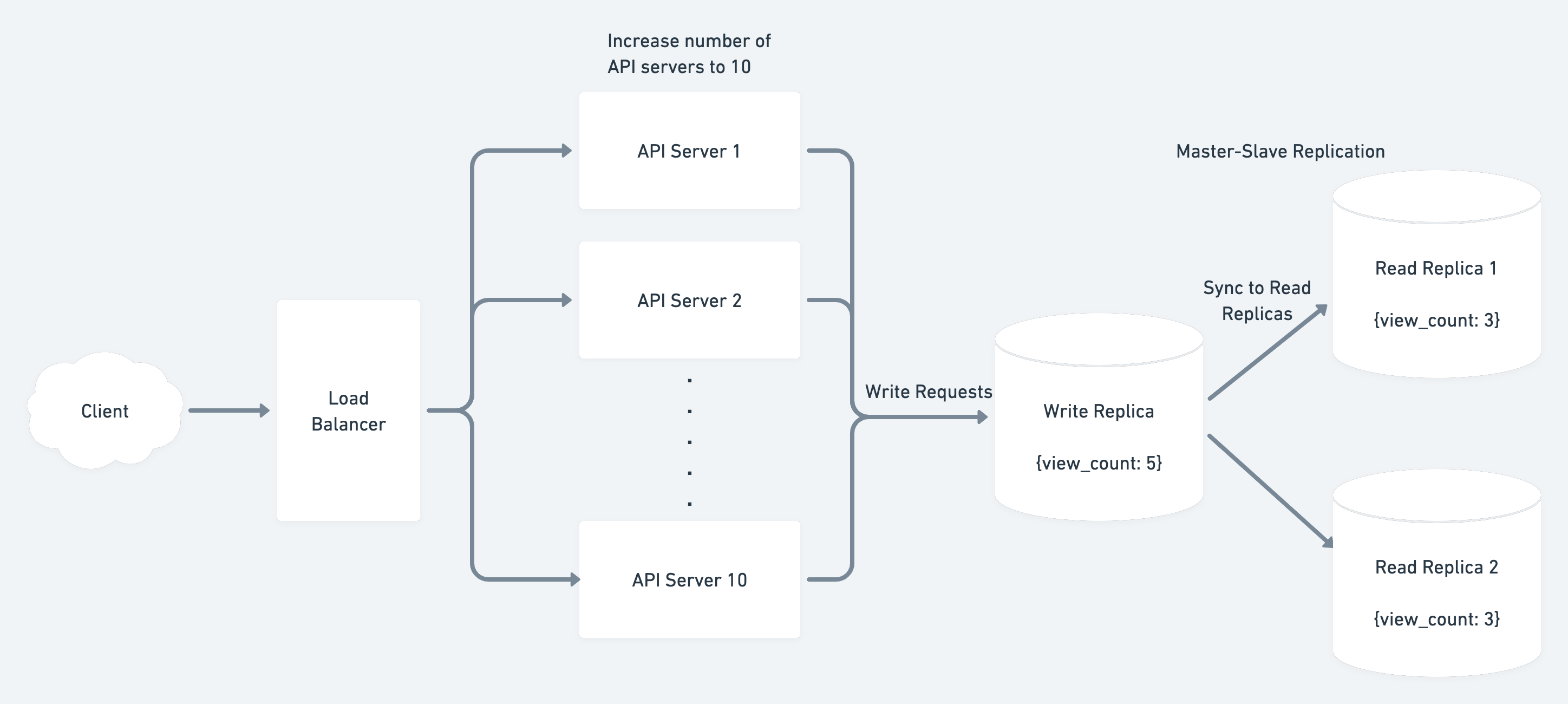
In the above diagram we’ve 1 Master and 2 Slaves. Having 1 Master ensures no conflicts. The Master node syncs the changes to the Slave nodes on every write.
Master-Slave Architecture
With Master-Slave replication we can process 200 read req/s. For scaling write requests we can do Vertical Scaling of the Master node or use Multi-Master config.
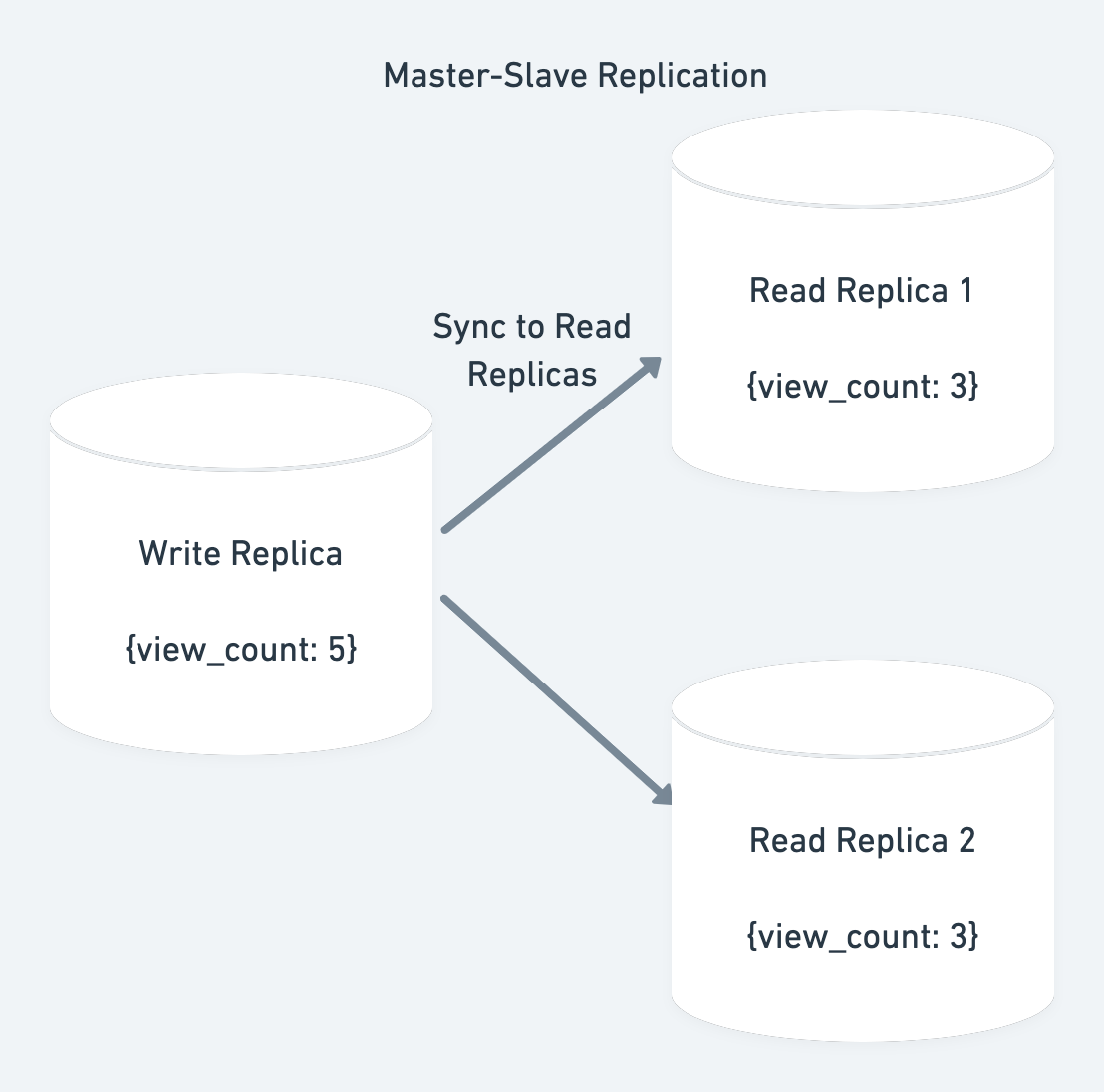
Since the data is across multiple nodes this is an example of distributed data system. Let’s discuss the challenges faced with such distributed data systems.
Challenges in distributed data systems
Networks are prone to connection failure. Due to this nodes in a distributed data system can get partitioned from the rest of the network.
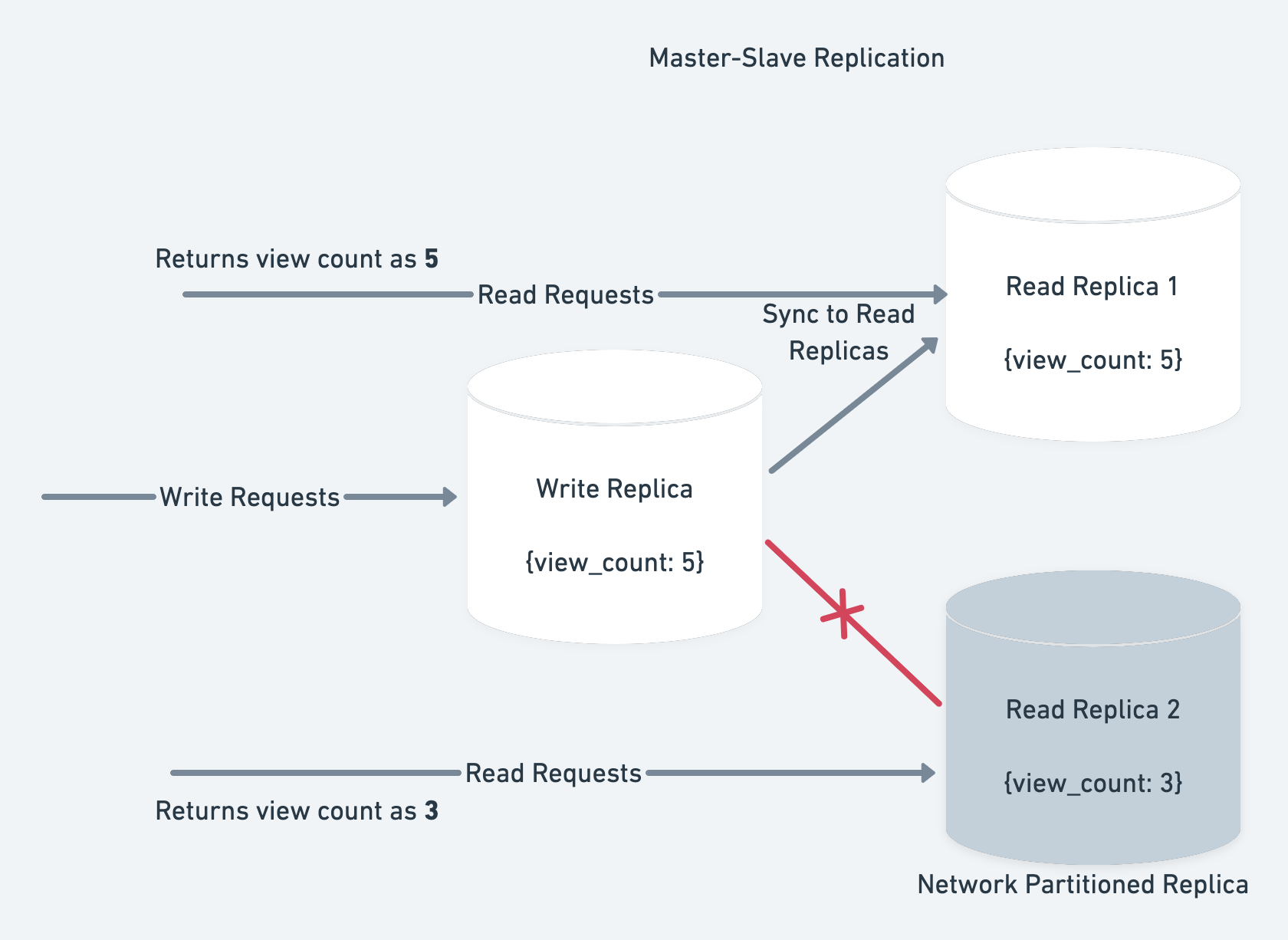
In our example, let’s say due to this the write node is not able to sync updates to one of the read nodes:
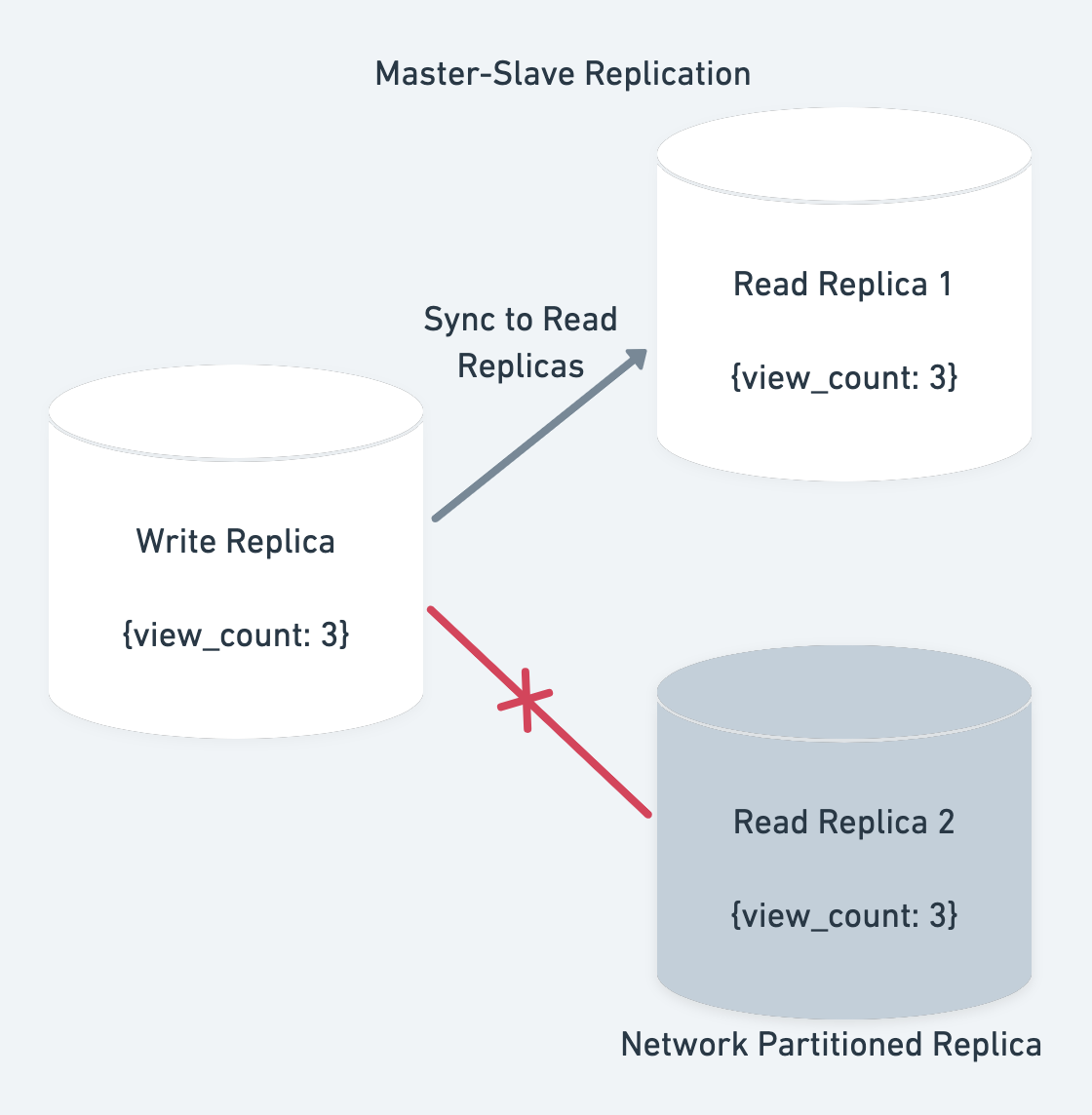
The read node can still process requests. The question is should we allow that or not ? Let’s compare the both the cases:
Case 1. Ensure Availability
Let’s say we allow the read requests. This means we’ve 2 read servers(slave nodes) available.
If an update comes to the write server. The write server will be able to sync it to R1 node but not to R2 node. Because of this R2 node will have inconsistent data.
So while R2 is available, it will not have consistent data.
Case 2. Ensure Consistency
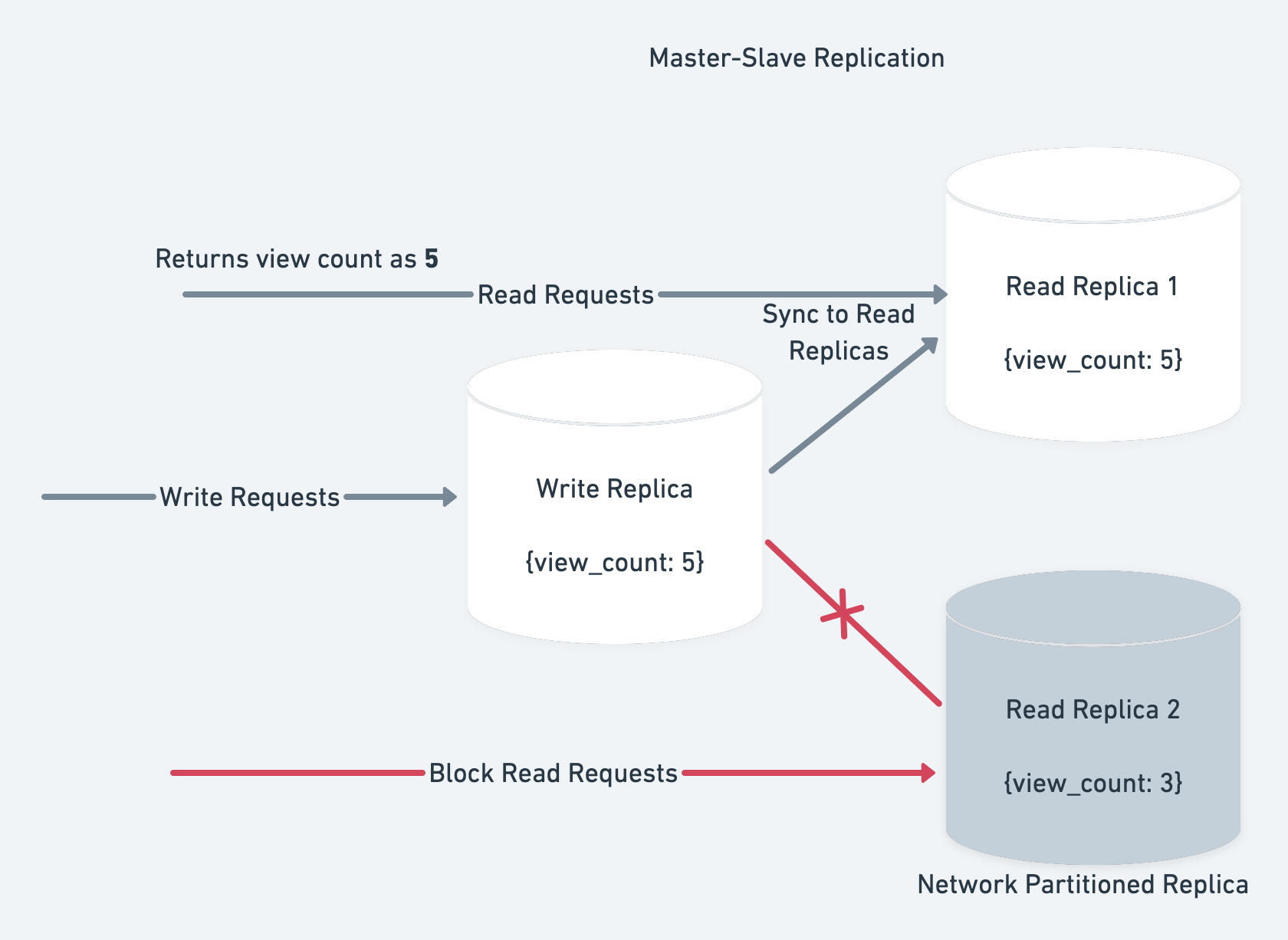
Let’s say we block the read requests to R2. This means we’ve 1 read server(slave node) available.
If an update comes to the write server, the write server will update R1 but not R2. As R2 is not receiving any requests the client will connect to R1 and see consistent response.
Here our system returns consistent data but R1 is not available.
CAP Theorem
The two cases we discussed earlier are example of AP system and CP system. As per CAP theorem in:
- AP - we don’t have Consistency.
- CP - we don’t have Availability.
When we only had a single database server there was no possibility of a network failure simply because there was no network. That is what is called a CA system.
For more detailed examples on CAP theorem refer this .
Summary
In this blog we covered basics of scaling:
- Horizontal and Vertical Scaling
- Stateless and Stateful Services
- Master-Slave Replication
- CAP Theorem
Hope you enjoyed learning these basics about scaling. Keep learning and have fun!