Microservices architecture is an architectural style that structures an application as a collection of distributed services. This allows better separation of responsibilities, greater flexibility in the choice of technologies for each service, and easier scalability and fault tolerance.
In simple terms in microservices architecture services have their own repository, dedicated cpu/memory, and may use different technologies and langauges depending on their usecase. While in monolithic architecture the services share the same codebase and cpu/memory.
Advantages of Microservices architecture
- Decoupling of systems allow choosing different frameworks/languages for the systems. For eg. one system can run on rails while another system can be run on go for higher concurrency.
- Deployments can be done independently.
- Hardware can be scaled separately for different systems. For eg. if a system generates report in memory then its memory can be scaled without affecting another system thus saving cost.
Disadvantages of Microservices architecture
- Deployment dependencies can become complex.
- Tracking bugs can be difficult as the whole tracelog needs to be tracked.
- Recreating bugs on local machine becomes tricky.
How to implement Microservices architecture
In Rails microservices architecture can be implemented using following techniques
Naive API solution
Calling another service using HTTP API calls can be used to make two services talk to each other.
This however will add IO wait on the api call since it’s a synchronous call.
Using background workers
Sidekiq is a common gem which is used to do background processing.
The idea is to create a sidekiq job to do the API calls. A system enqueues the payload to sent to another system to a sidekiq job and then the sidekiq job makes the API call asynchronously.
Advantages of using background workers
It prevents IO wait due to being asynchronous in nature and allows retries if the target system is down.
Disadvantages of using background workers
- The calls are not guaranted to be in order.
- Sidekiq uses Redis to store info of enqueued background jobs making Red as the single point of failure. This can be prevented to certain extent by making backup of Redis and adding retry to background jobs, however, there will be some downtime.
Using message queues
Message queues is similar to using background processing.
It uses the concept of producer and consumer where the source service is the producer and target service is the consumer. Producer enqueues the payload into the message queue and the consumer reads the payload from the message queue.
Advantages of using message queues
- This approach guarantees that the payload are processed in order.
- Allows retrying by deleting the payload in message queue only when consumer has processed it successfully.
- Additional message queues can be added for scaling.
- Message queues can be backed up in case message queues goes down.
Disadvantages of using background workers
- Adds complexity to the architecture.
- Additional latency is not ideal for real time services.
Understanding the above approaches with real life example
Let’s take an example of a logistics management app which has a shipper service and a carrier service. The shipper creates a delivery and tenders it to one or more carriers, then atmost one carrier accepts the delivery.
Here’s how the interaction looks like:
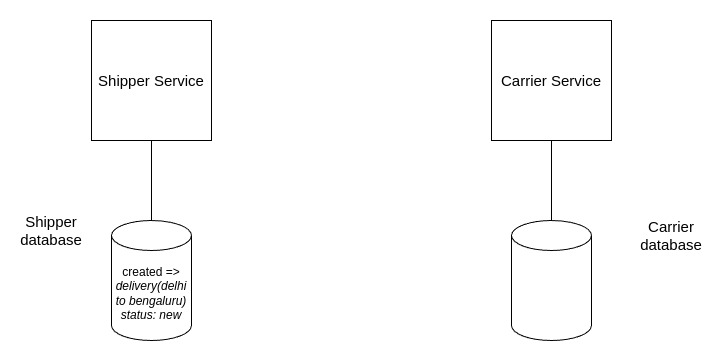
- Shipper creates a new delivery from Delhi to Bengaluru.
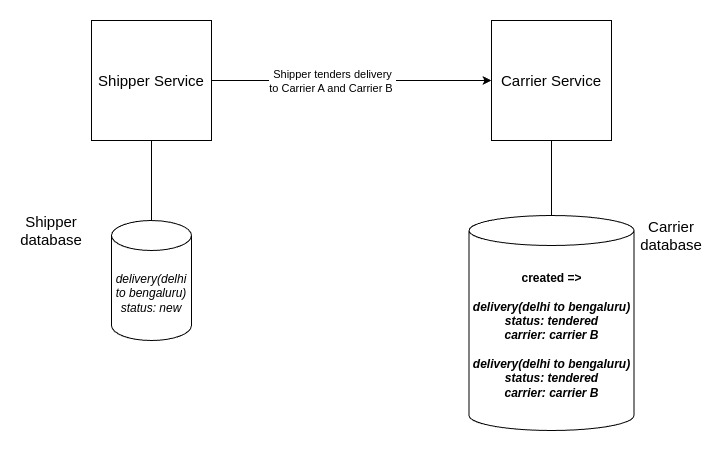
- Shipper tenders delivery to carrier A and carrier B.
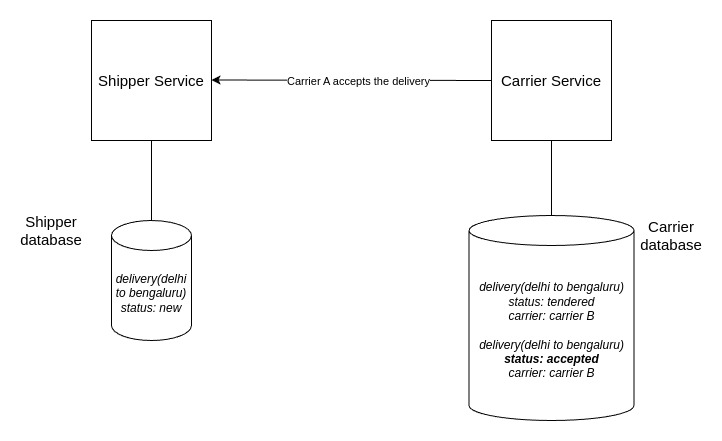
- Carrier A accepts the delivery.
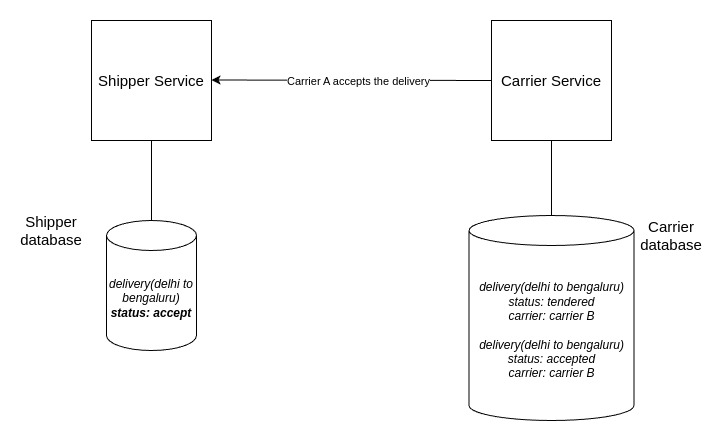
- Delivery’s status is set as accept in Shipper.
Now let’s solve the above use case with the previous approaches for interaction between microservices:
Naive API solution
In naive API solution http api calls are dispatched for tendering. Let’s assume a non-threaded environment, in which case tendering for carrier A will be done and then carrier B will be done.
Here’s how it happens:
- http api call to tender the delivery to carrier A is dispatched, while this is being processed by the carrier the http api call for tendering to carrier B is in IO waiting.
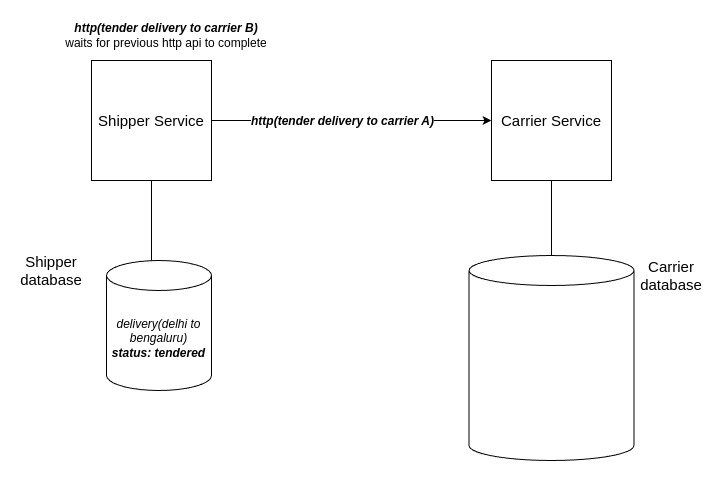
- Once the carrier A http api call is processed, the tendering http api call for carrier B is dispatched.
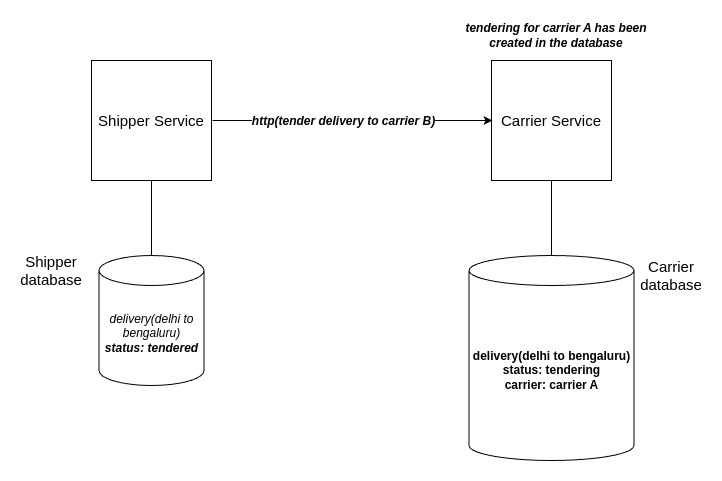
We can see here that request for carrier B waits on completion of carrier A’s request. This can improved by using multi-threaded environment which prevents IO wait.
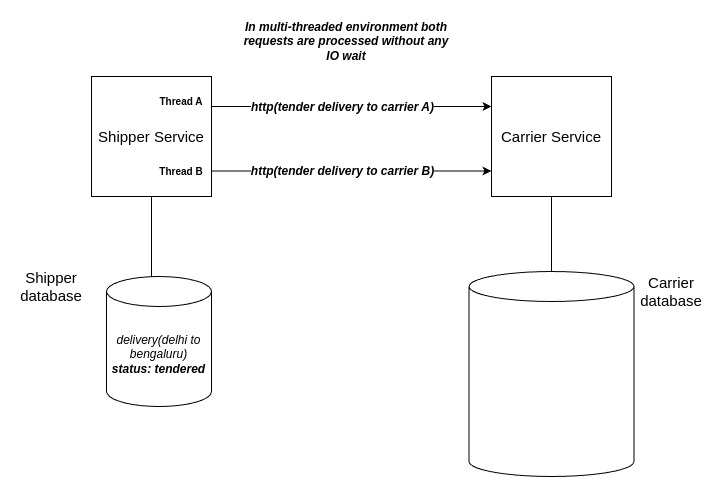
There are few disadvantages of this approach:
- There’s load on both shipper and carrier since until the request is complete both of them will have the thread alive.
- If the carrier service is down there is no way for retrying the request.
Using background workers
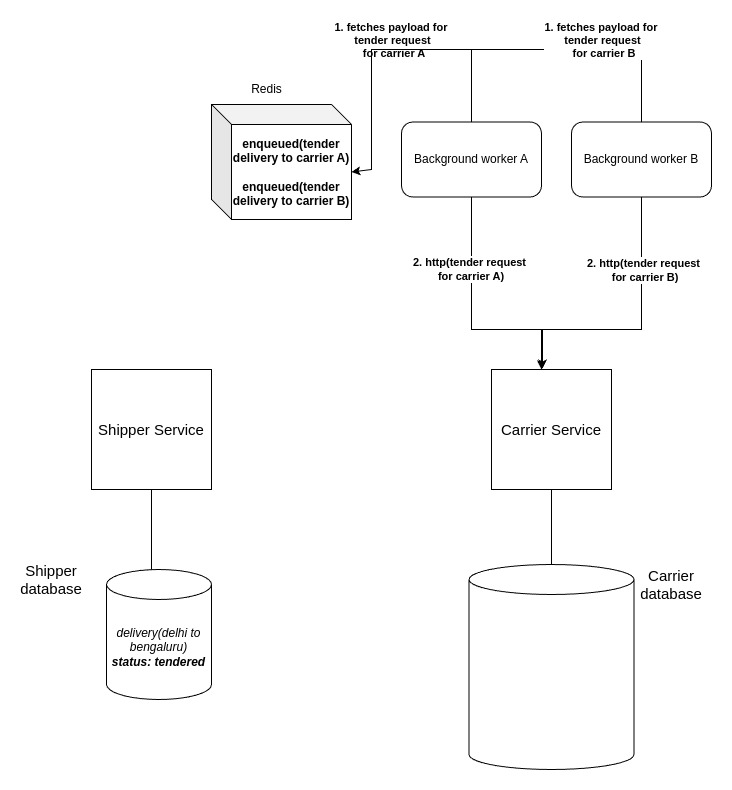
The idea with using background workers is to enqueue the payload of the http api call into a cache and giving background workers the responsibility to dispatch the http requests.
There’s a popular gem called Sidekiq which uses Redis for background processing. Here’s how it will work:
- Shipper service enqueues the tendering request for carrier A and B in redis.
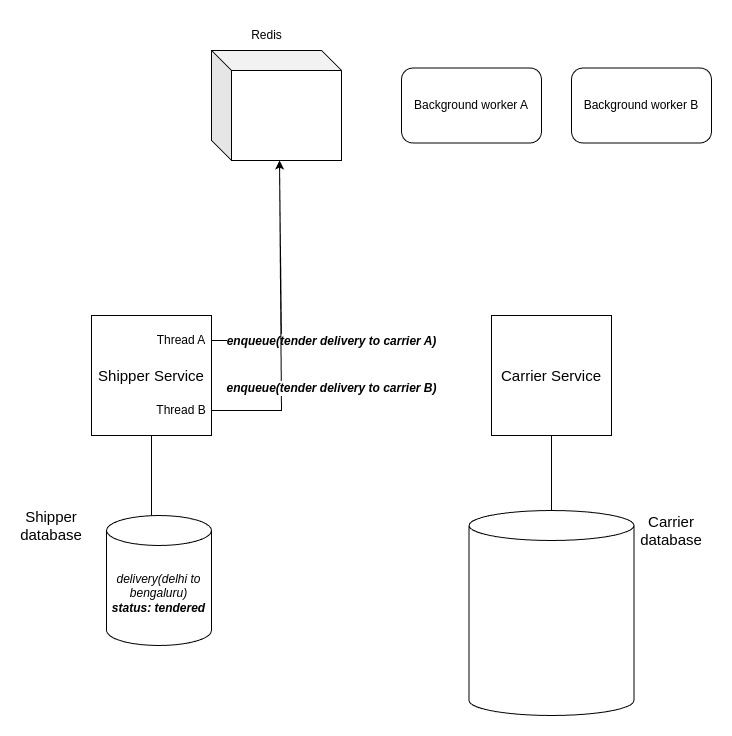
- The background workers fetches the payload for carrier A and B and processes them in separate workers by dispatching http api calls for them.
Advantages of this approach over previous one is:
- The Shipper service doesn’t incur the load for making http api calls which is delegated to the background processing jobs.
- If the Carrier service is down the background workers can put the payload back into redis for retrying after some time.
- More background workers can be spawned to handled more number of requests.
This approach still has some disadvantages:
- Since any background worker can fetch any tendering request from redis there is no guarantee that the requests will be processed in the order in which they’re put in redis.
- Redis is the single point of failure here. This can be reduced by taking backup of redis and allowing retries.
Using message queues
Message queues uses the concept of producer and consumer. In our example the Shipper service acts as the producer and the Carrier service acts as the consumer.
Here’s how it works:
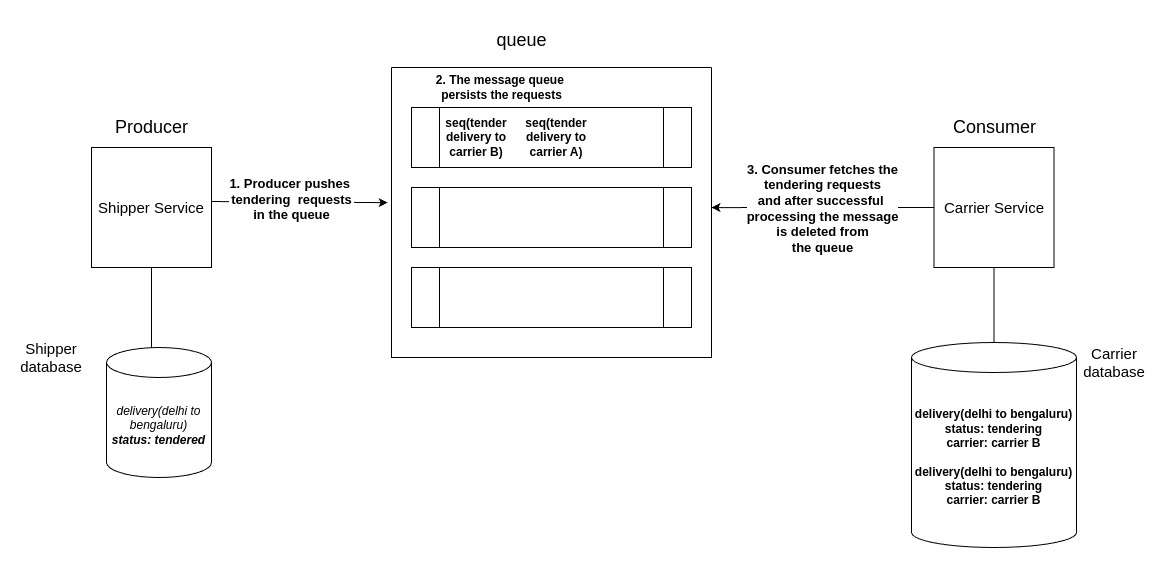
Advantages of this approach are:
- Message queues can be scaled to handle increased load.
- The messages are processed in the order they’re pushed in the queue. This is done using sequence numbers.
- Messages are persisted in case of failures so consumer can retry processing them.
Disadvantages of this approach:
- If the consumer processes the messages slowly or producer is creating too many messages then the queue can be overloaded.
- The message queue architecture adds complexity and there is a significant overhead to maintain it.